Hi @ultraman
Thank you for your message.
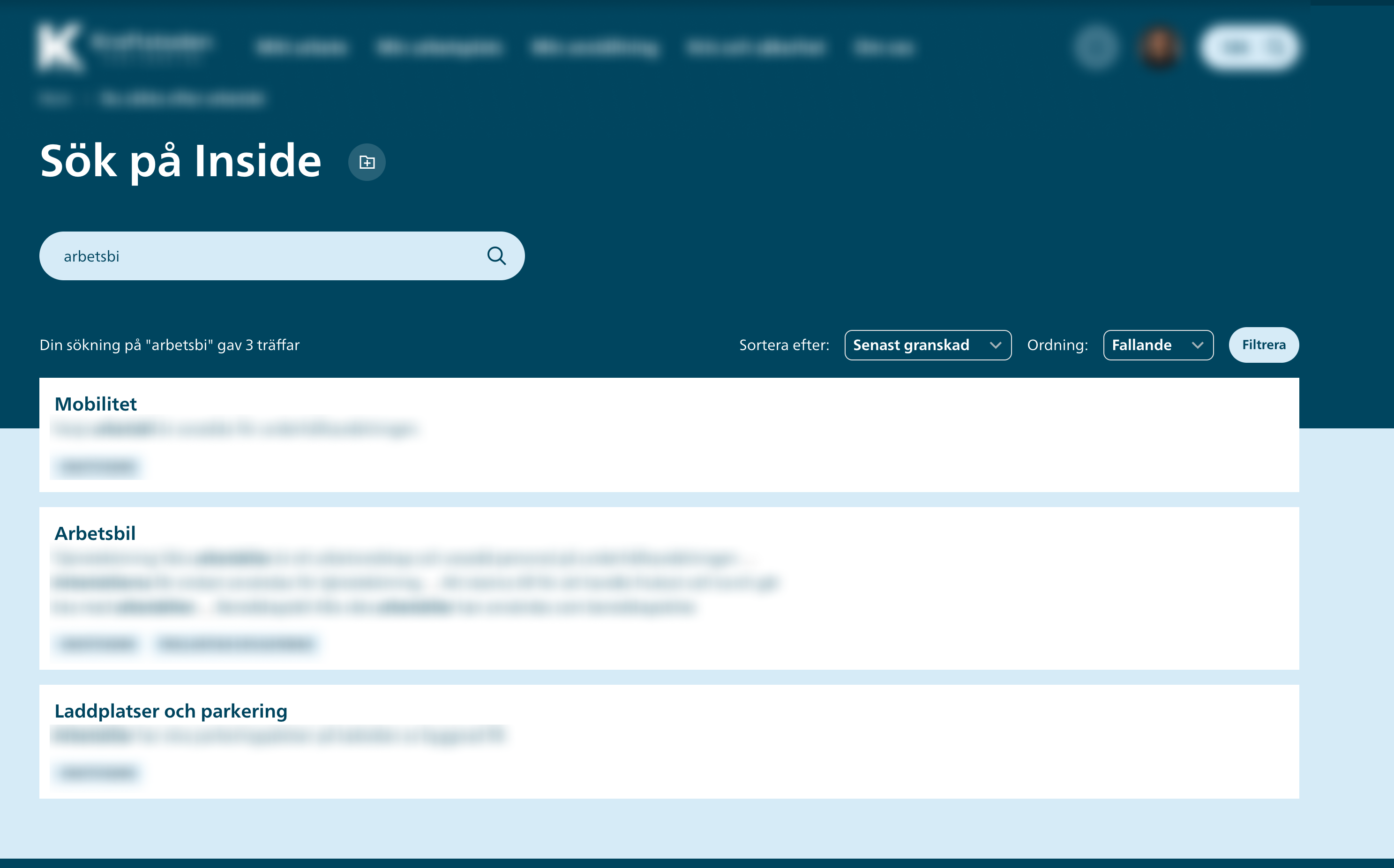
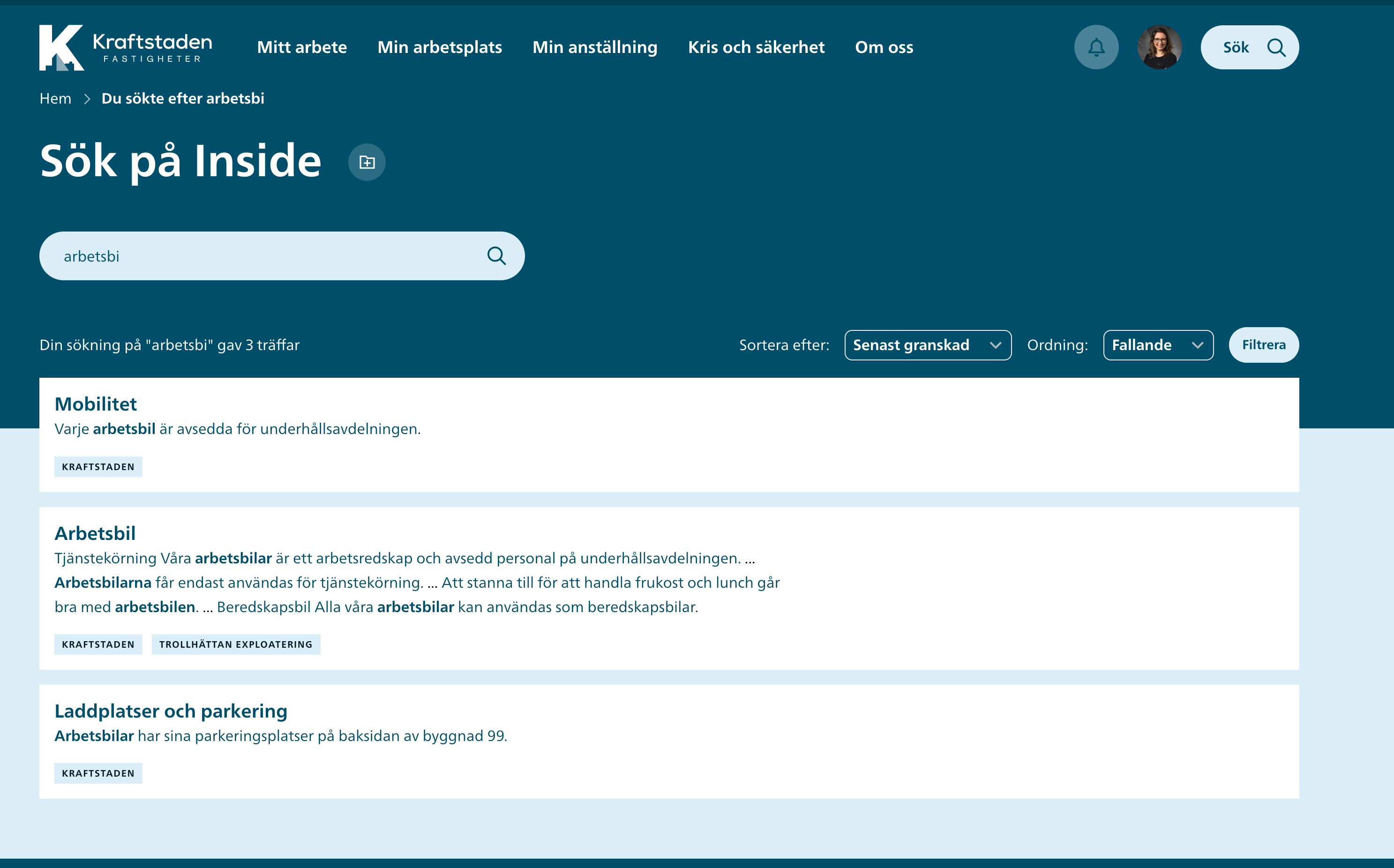
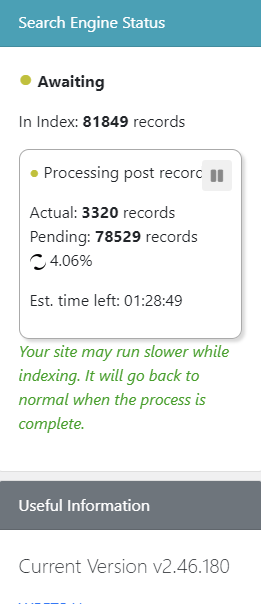
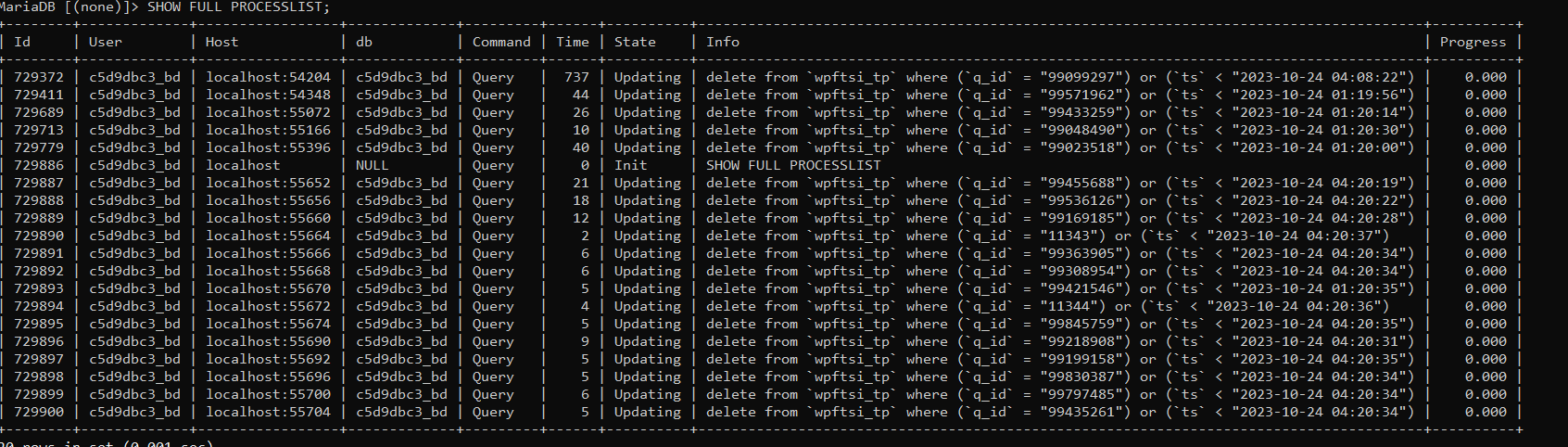
Since you can see results in the Sandbox, the index is fine. No need to rebuild it again. The problem is on the "display results" side.
With your configuration, the first idea I think is to install the pre-release WPFTS version that contains the latest fix of the Divi Addon for WPFTS. I've sent you the link in private messages.
Please install it and tell me if it works fine or not.
In case it still does not work, please tell me which version of Divi Theme you are using, the WPFTS plugin version, and also please explain your search behaviour. Simple try the request like this:
https://yourdomain.com/?s=<search_phrase>
And notice if it returns any result.
Thank you!