Get WPFTS Pro today with 25% discount!
Causes garbled characters
-
Hi @enya
Could you please show me some screenshots? Preferrable a part of the PDF / Excel file and how it looks on search.
Thanks!
-
@epsilonadmin
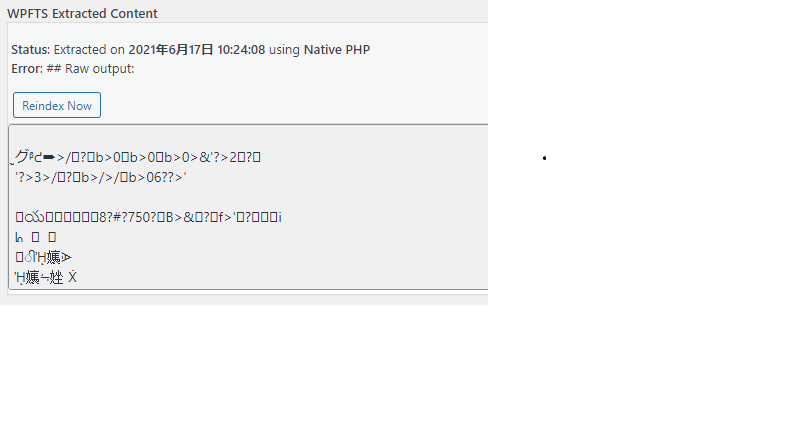
Here is the index of garbled PDF data. Is it possible to set Native PHP so that it does not get garbled? -
@enya
Unfortunately, the NativePHP parser for PDF is not that good. It still works for most PDFs but fails on some of them. Also, it does not support Excel file parsing.We have created Textmill.io service because it's much more powerful and does this job much better.
Did you try to switch on Textmill.io?
-
@epsilonadmin
Yes, I did. It worked fine with Textmill.io. However, we are worried about security, so we would like to operate with Native PHP. -
@enya Could you send me an example of that PDF file to the epsiloncool@gmail.com or via private message in forum chat. I need to make some tests.
-
@epsilonadmin
This is a sample, but I will send it. Thank you.bantekansan.pdf -
@enya
I'm sorry, the quality of the data I passed last time was not good, so could you try it with this data?テスト用のデータ.pdf -
Hi @enya
Okay, I am still looking for a solution to this. -
@epsilonadmin
Thank you very much. -
@enya
Another question is, in which php file is the code that recognizes the pdf text when NativePHP is applied? ?? -
Hi @enya
We are using ready library pdf-to-text by Christian Vigh. It's in the /classes/ folder of WPFTS plugin. -
@epsilonadmin
Thank you very much. Let's take a look at the contents. -
@enya
I'm new to PHP so I'm sorry if I made a mistake. I think I'm converting the character code between lines 282 and 315 in PdfToText.class.php. How can I make the character code such as Shift-JIS convertible here? ??
I'm sorry if it's not the content to ask here. -
Hi @enya
Hmmm, sorry I am not an author of this library and unfortunately, I can't say which internal logic the author means here. The WPFTS Pro is just using it "as is". Actually, this way is just a fall-down method, because it's intended to use Textmill.io in most cases.
-
@epsilonadmin
Is there a possibility of security problems using TextMill.io when uploading confidential data? ?? -
Hi @enya
We are preparing the official Privacy Policy document now, that will describe most part of Textmill.io functionality.
The main thing I would explain is this:
Textmill.io does not store any data. When any file is uploaded to the service for text extracting after the conversion and converted text responded to the caller (to WPFTS Pro instance) all data is removed.Nothing stored means nothing will be stolen etc.
Textmill.io also uses HTTPS and protected servers.
Yes, I would not recommend it for very important secret documents (military, government, etc). But I also think that these companies that manage such information do not use Wordpress at all and have enough money to create their own protected systems and CMSs.
Wordpress itself is not that protected and safe. Any small code stored in the 3rd-party plugin may share any information on the internet.
-
@epsilonadmin
Thank you very much. I was relieved to know that it was strong in terms of security.
In which code part of fulltext-search.php is the character data extracted by PdfToText.class.php used? ?? -
Hi @enya
Half of the plugin is the indexer. It would be too long to explain how it works.
I think you need to see the code of /extractors/native.php
It's a wrapper for NativePHP extraction that uses the PdftoText library and then sending ready data to the indexer. -
@epsilonadmin
Thank you very much for your kindness. I'll take a look.