Get WPFTS Pro today with 25% discount!
PDF Search Results: Titles and Excerpts
-
I have a couple of problems with the way WPFTS displays search results from my Society's website (https://rchs.org.uk/). By way of background, the key reason I installed WPFTS was to search the over 200 Society Journals, which have been uploaded as OCR-ed pdf files on to the website. Each Journal has around 100 pages, and contains about 10 articles, each of which is bookmarked. Unfortunately, the filenames, and the folder structure, were not developed with WPFTS in mind and, therefore, are not intuitive. This has not been a problem thus far, as each Journal is accessed via a table on a web page containing the real title of the Journal, and a hyperlink to the pdf. Once the pdf is open, the reader can then either scroll to the contents page, or use the bookmarks, to find the article of interest. (We also have indexes, or various qualities, to the Journals and these are also stored as pdf files.
My first problem is that a WPFTS search displays the filename as the header, and this is meaningless in many cases on my website. I could rename all the files and amend the hyperlinks, but this is quite a big job. Would it be possible for WPFTS to display an alternative header; perhaps either the Title contained in the document properties of the pdf, or the first bookmark? Better still is the search would take the reader directly to the relevant bookmarked article in the Journal.
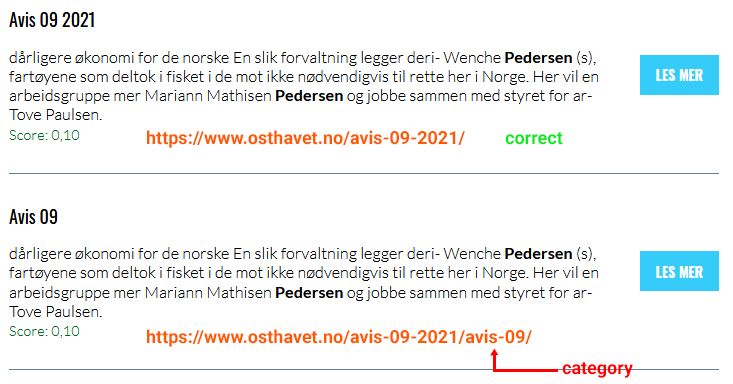
My second problem is that where the 300 [character?] Optimal Length text excerpt should be, I am just seeing a date which looks like the date the file was uploaded to the website. See the screen grab below as an example.
Any advice gratefully received.
-
Hi @Nick
It seems to be you're using the Avada theme, which has known conflict with the Smart Excerpts algorithm. Please consider checking this topic to find the proper solution.
Renaming Media titles would be the good and clean solution, however, we still could try to extract magazine titles from the PDF. The PDF format is a bad way to store layout data because on the extraction phase it normally loses all the structure, so extracting a part of text could be not a simple and straightforward task. But we can try. Could you send me one of two files just to check if we can get a title from the extracted text or not?
Additionally, you can try to open the Edit Attachment page for those files in your WP admin and find the "WPFTS Extracted Text" window there. The magazine title should be somewhere in the first row of text. If so - we can build the algorithm which will extract this header.
As for opening the file exactly on the page where the text was found - we are working on this function at the moment, an alpha version for testing will be ready very soon. We'll let you know as soon as it's ready.
Please let me know if Avada theme fix works for you.
Thank you!
-
@EpsilonAdmin: thanks for your advice. I'll get the Avada fix done, and let you know if this solves the excerpts (text) issue.
Aa a trial, I've amended the Titles of the first two Journals on our website, and WPFTS now displays these titles, so it appears that this will solve the WPFTS title issue.
I'll be going through all of our uploaded Journals in the coming weeks, checking for significant OCR errors, and correcting them. We may decide to rename the files and links during that process, but amending the title seems to work anyway.
I'm attaching pdf copies of our first two Journals. They were very simple back in 1955, but duplicated, so I've had quite a lot of work to do correcting the OCR text in these. The uncorrected version, but with the title updated, is still on our website. One error is that "Wimbledon" is the correct word in the attached pdf of Journal 001, but the website version has "7imbledon". If you search for "7imbledon" on our website, it should bring up just one result, in Journal 001.
I tried to upload the two Journals (see below), but got an Error message stating that Uploads are Disabled.
Thanks again, Nick
![alt text][0_1597754839656_Journal 001 - January 1955.pdf](Uploading 100%)
[0_1597754881159_Journal 002 - April 1955.pdf](Uploading 100%) -
Hi @Nick
Please try to upload the files again. I've enabled uploads.
-
Thanks. I've now had the Avada fix applied, and the 300 character text is displaying. Great!
I'm attaching the two files mentioned above. These are the corrected versions, so are slightly different to those on the website. In particular, in the Document Properties of the website file, the filename is just repeated (is this done automatically?), whereas on the corrected version I have amended the title to something more meaningful. In both cases, it is the Title that is displayed in the search results.Journal-001 Jan 1955.pdf Journal-002 Apr 1955.pdf -
Hi @Nick
Did you solve the issue? I think we can extract the title from the PDF metadata. Just a little script will be required for that.
Let me know if you still looking for a solution.
Thanks!
-
Another thing we detected with the Avada theme: sometimes people changed the internal theme settings and still think the website Search works wrong because of WPFTS issues.
Well, in the Avada theme there is a Search settings (you can navigate there by Main Menu > Avada > Theme Options > Search Page). There are two options that you should care about: "Search Results Content" and "Search Results Excerpt".
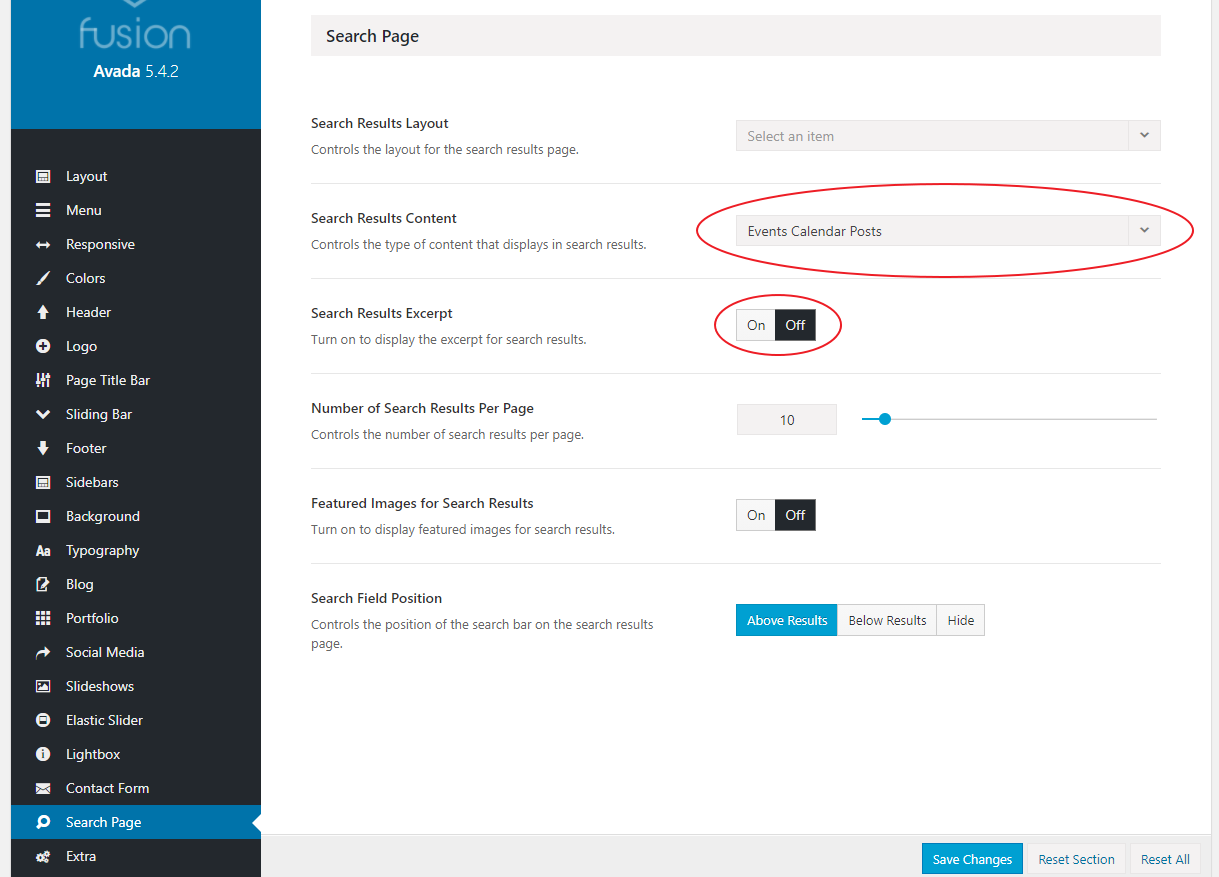
These options are not conflicting with WPFTS Pro, however, if you disable the Excerpt, it will not be shown on the Search Results page.
Also, if you disable a specific post type in "Search Results Content", it will be not shown too.We would propose to set them to "On" and "All Post Types and Pages" respectively. Please see another screenshot:
![E20201017-224229-001[1].png](/forum/assets/uploads/files/1602962173729-e20201017-224229-001-1.png)
Hope this will help you to avoid some issues with WPFTS Pro and Avada theme.
-
Many thanks for the advice. We've implemented it, and our search results now show in a single column across the page, which is exactly what we wanted.
-
We now just need to work out how to reduce the font size in the Title, and the amount of blank space beneath it.

-
Hi @Nick
This should be done via your theme's CSS styles. If you don't want to edit your theme's styles, you can use the CSS snippet which is on the Display tab in WPFTS Settings / Search & Output.For example, this CSS should work for you
#main .post h2.fusion-post-title a { font-size: 21px; } #main .post h2.fusion-post-title { margin-bottom: 5px; }You could justify 21px and 5px to make a different title size and the bottom margin respectively.
-
@EpsilonAdmin said in PDF Search Results: Titles and Excerpts:
#main .post h2.fusion-post-title a {
font-size: 21px;
}
#main .post h2.fusion-post-title {
margin-bottom: 5px;
}Thank you for your further advice. I added your code to the end of the code in the Custom CSS Styling dialog, but decided that a font-size of 20px, and a margin-bottom of 0px, worked best for our website. The results can be seen by inserting some text (try "Worcester") in the search box that is top-right here: https://rchs.org.uk/
-
Great, thanks!
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login